Deep Learning Frameworks Race
Most deep learning developers find a DL framework invaluable, whether for research or applications. There’s been great retrospective analysis of framework adoption, for example Github activity whether by Jeff Dean for Tensorflow or more broadly frameworks by Francois Chollet. The topic here is emerging changes – how DL frameworks are distinguishing themselves by incorporating a new tool, the NCCL library and what that means for training DL networks. Namely, MPI-like GPU collectives are now currently supported by Tensorflow, Caffe 2, Caffe, Theano, Torch, and MxNet to varying degrees for multi-GPU applications.
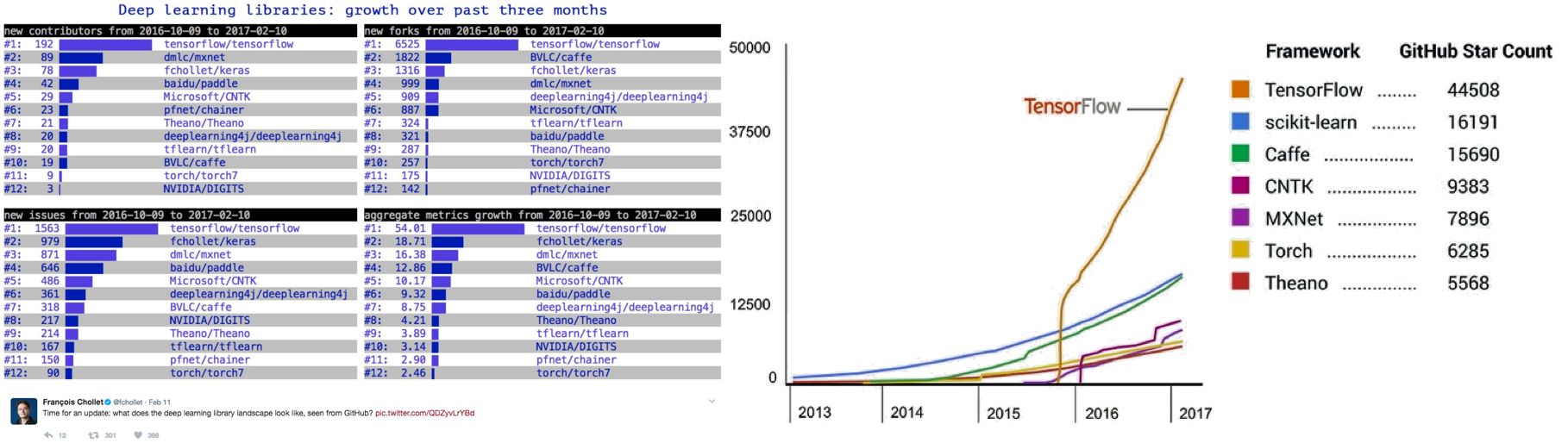 Jeff Dean and Francois Chollet from Google have indicated relevant DL framework statistics for adoption
Jeff Dean and Francois Chollet from Google have indicated relevant DL framework statistics for adoption
For an excellent introduction to the NVIDIA communication collectives library or NCCL https://github.com/NVIDIA/nccl, the NVIDIA developer’s post has common uses cases and technical diagrams: https://devblogs.nvidia.com/parallelforall/fast-multi-gpu-collectives-nccl/. The U.S. Department of Energy backed the original proposal through the Lawrence Berkeley National Laboratory and in a similar spirit NVIDIA has opensourced the implementation.
The NCCL library is fundamentally helpful to distributed DL training, which is described here http://leotam.github.io/general/2016/03/13/DistributedTF.html. Particularly, model-parallelism, that is placing parameters of deep neural networks on separate GPUs, require frequent synchronization. In data parallelism, the broadcast operation may be used distribute an averaged gradient to each of the models. Tim Dettmers covers how an all reduce is performed to synchronize the weights for each gradient http://timdettmers.com/2014/10/09/deep-learning-data-parallelism/.
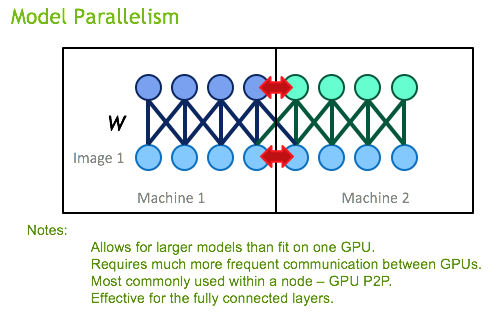
In lockstep, the DL frameworks developers have realized the tremendous value in the NCCL library, rapidly incorporating it. A list of implementations is:
Caffe: https://github.com/BVLC/caffe/blob/master/include/caffe/util/nccl.hpp
Tensorflow: https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/nccl
Caffe 2: https://github.com/caffe2/caffe2/tree/master/caffe2/contrib/nccl, https://github.com/caffe2/caffe2/blob/master/caffe2/python/data_parallel_model.py
CNTK: https://github.com/Microsoft/CNTK/wiki/Setup-CNTK-on-Linux#optional-nccl
Theano: http://deeplearning.net/software/libgpuarray/installation.html?highlight=nccl
Prototype of Theano for multi-GPU and multi-Node also relies on NCCL: https://github.com/mila-udem/platoon
Torch: https://github.com/ngimel/nccl.torch, https://github.com/NVIDIA/torch-nccl/blob/master/test/testnccl.lua
Chainer: https://github.com/pfnet/chainer/pull/2213
Mxnet: https://github.com/dmlc/mxnet/pull/5521
The implication for DL training is that the next level of rapid large models is accelerated at a fundamental mechanistic level. Rarely does the software tooling match leading implementations due to hyper-focused execution in an application space. In terms of the hardware, better interconnects, such as NVlink http://www.nvidia.com/object/nvlink.html, are great targets for NCCL.
 NVLink, high-speed GPU interconnect baked into the DGX-1 http://www.anandtech.com/show/10229/nvidia-announces-dgx1-server
NVLink, high-speed GPU interconnect baked into the DGX-1 http://www.anandtech.com/show/10229/nvidia-announces-dgx1-server
ADDENDUM
Furthermore, it’s straight-forward to install NCCL on a multi-GPU system to examine communication. For example, after cloning the repository:
cd nccl
make CUDA_HOME=/usr/local/cuda test
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:./build/libWith some sample tests as:
./build/test/single/all_reduce_test 10000000Which would issue output similar to:
/home/nccl/build/test/single# ./all_reduce_test 10000000
# out-of-place in-place
# bytes N type op time algbw busbw res time algbw busbw res
10000000 10000000 char sum 0.286 34.98 52.47 0e+00 0.303 32.98 49.46 0e+00
10000000 10000000 char prod 0.291 34.31 51.47 0e+00 0.309 32.36 48.54 0e+00
10000000 10000000 char max 0.286 34.95 52.43 0e+00 0.306 32.69 49.04 0e+00
10000000 10000000 char min 0.289 34.65 51.98 0e+00 0.304 32.85 49.28 0e+00
10000000 2500000 int sum 0.283 35.35 53.02 0e+00 0.298 33.53 ...