10 Papers from ICML and CVPR

The International Conference on Machine Learning (ICML) and Computer Vision and Pattern Recognition (CVPR) 2016 occurred back-to-back this year. In this post, I’ll cover some of the most exciting advances in research as experienced from an on-the-ground perspective. Unsurprisingly, ICML focused more on fundamental research in an intimate setting while CVPR focused on applications research. Both included copious amounts of deep learning applied to many different areas.
ICML

Set in Times Square, it was a trivial task to screen out the constant flood of tourists with great research in the forefront.
In general, ICML felt intimate (despite significant growth) and top researchers were accessible for informal ad-hoc conversations and brainstorming. It’s probably an inflection point before this conference gets too crowded.
Top papers and presentations
Kaiming He’s Deep Residual Networks tutorial revealed tips and tricks for training ultra-deep residual networks. First presented at ICCV 2015 where he did his first victory lap for winning the 2015 ImageNet competition, Kaiming kept it interesting with a few neat points. For instance, cutting out to a video demonstrating the layer by layer variance visualization. CVPR would later show that ResNets are incredibly important and experts must reduce it to practice in order to obtain leading results. Kaiming He’s ResNet Tutorial
As always, David Silver gave one of the best presentations on deep reinforcement learning. It was just the start of great presentations from Google Deepmind spanning the entire week. He closed the sessions with details from their AlphaGo work. David Silver’s DRL Tutorial
For instance, Dueling DQNs for reinforcement learning was uploaded awhile back on arxiv, but still relevant. Salience maps between advantage and value streams show difference between local and global (equivalently near and far) optimization. One weakness of the approach is games requiring leaps in strategy exploration. http://arxiv.org/abs/1511.06581
Leon Bottou’s presentation on accelerating DNN training uses optimization surface curvature information to speedup optimization, descending more quickly where the topology allows. He showed numerical results confirming his theorems that natural gradient methods allow scaling proportional to weights instead of neurons. “Three observations on diagonal second order methods applied to deep networks” http://arxiv.org/abs/1606.04838 Related work: http://arxiv.org/abs/1301.3584
G-convs as a drop-in replacement for standard convs, consistent improvements in accuracy and ties to Lie algebra. Open source: https://github.com/tscohen/GrouPy https://github.com/tscohen/gconv_experiments https://staff.fnwi.uva.nl/m.welling/wp-content/uploads/papers/icml2016_GCNN.pdf
Stacked what-where autoencoders reducing sampling during training and tested on an open dataset. On GitHub here: https://github.com/YutingZhang/caffe-recon-dec https://arxiv.org/abs/1506.02351
Concatented ReLUs as an easily implemented, low cost layer improvement http://jmlr.org/proceedings/papers/v48/shang16.pdf
Sashank Reddi presented Stochastic Variance Reduction for Nonconvex Optimization SVRG, emerging as the most promising candidate to supersede stochastic gradient descent. http://suvrit.de/papers/nonconvex_svrg.pdf
Ivo Danihelka presenting associative LSTMs used complex-valued vectors for a general, low cost, and parallelizable way of adding memory to LSTMs for longer recall (for instance to improve performance through noise reduction from multiple copies) http://jmlr.org/proceedings/papers/v48/danihelka16.html (Edit: uLSTMs may have better performance, Oriol Vinyals commenting here)
In the meetups surrounding ICML, Leo Dirac from Amazon gave a great talk on DSSTNE at scale. He gave practical guidelines on scaling limits and referenced Nikko Strom’s work on reducing weight updates.
One of the hidden highlights was the systems session at the Friday workshop (for the intrepid few that had enough steam after a full week). One trend is increasing the accessibility for data scientist use, ie. FBLearnerFlow, ModelDB, and KNIME. Soumith Chintala mentioned in his presentation the aggregate community numbers are the ultimate judge of success for an open source project. Databricks emphasized Spark is maintained under the Apache Foundation which guarantees stable governance. Poseidon was presented as an off-shoot of Bosen and Pentuum addressing distributed training by extending Caffe with tests on ILSVRC2012 and ImageNet 22K: http://arxiv.org/abs/1512.06216
 Well played, well played. Stanford Professor Feifei Li closed her ICML talk with quite the quip at Trump, who spoke earlier in the day in the same venue.
Well played, well played. Stanford Professor Feifei Li closed her ICML talk with quite the quip at Trump, who spoke earlier in the day in the same venue.
CVPR
CVPR of course has a different focus, namely applications of computer vision through which deep learning techniques lead in image classification, object detection, semantic segmentation, multi-modal analysis, etc. An excellent collection of open source tools released at CVPR is available here
Top papers and presentations
Jiwon Kim’s Deeply-Recursive Convolutional Network for Image Super-Resolution provided some perhaps well-known tips on training such as gradient clipping and learning rate annealing. http://arxiv.org/abs/1511.04491
There were a few interesting new layer types such as Magic Pony’s (Wenzhe Shi) Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network, Gaussian Conditional Random Fields (http://ravitejav.weebly.com/uploads/2/4/7/2/24725306/segmentation.pdf) in many talks, and dynamic parameter hashing layer (http://arxiv.org/abs/1511.05756).
Single Shot Detection squared off against You Only Look Once. (http://arxiv.org/abs/1512.02325 and http://arxiv.org/abs/1506.02640).
LocNet is used to improve bounding box accuracy. Next time, you’re inspecting an object detection demo, pay attention to the tightness of the bounding box! https://github.com/gidariss/LocNet
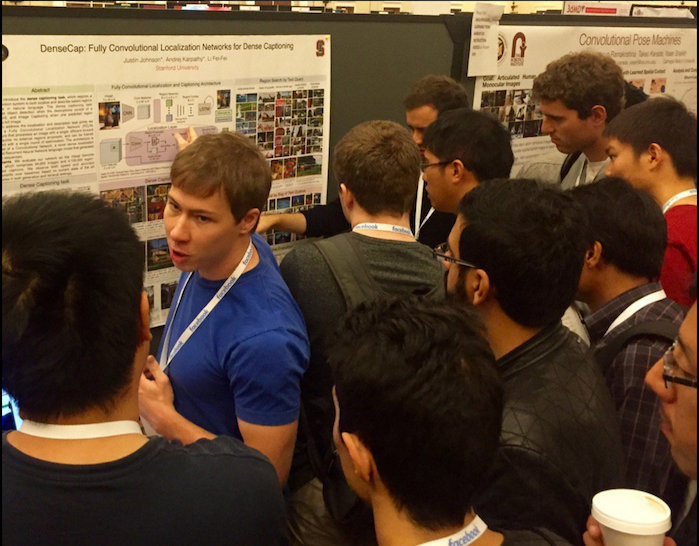
Hopefully, this dynamic duo will continue their collaborations! https://arxiv.org/abs/1511.07571 Open source https://github.com/jcjohnson/densecap
Wonmin Byeon presented PyraMiD-LSTMs (first shown at NIPS) which had a warm reception here. PyraMiD-LSTMs have one of the top results on medical image segmentation and are highly parallelizable for 3D scans. https://arxiv.org/abs/1506.07452
ResNets are now everywhere. The community has overcome any difficulty in training and using them in nearly all top accuracy applications using pre-training or training from scratch. For instance, they were prevalent in the Visual Question and Answering challenge as seen from the summary of approaches on the leaderboard.
Training Region-based Object Detectors with Online Hard Example Mining to improve CNN object detection from Facebook AI (https://arxiv.org/abs/1604.03540) stirred some memories. We had used hard positive mining to improve classifcation of retinal images (presentation here, slides here).

The NVIDIA T-shirt. Adam Nash on the importance of a good t-shirt: https://blog.adamnash.com/2010/11/29/why-t-shirts-matter/
Here’s another good CVPR 2016 summary from a Quora post. OK! That was a few more than 10 papers, but the field is moving fast.