FP16 on embedded Jetson TX1

Image courtesy Dustin Franklin
The 2016 Embedded Vision Summit recently took place in the heart of Silicon Valley. The summit started with a bang when Jeff Dean announced some impressive results using reduced precision deep learning models for inference. For embedded and edge applications of deep learning models, reduced precision inference is a big deal. A brief primer is that model size is reduced by four times since normally single precision uses 32 bits per value. The power draw is significantly reduced as 16 bit arithmetic is nearly two times as fast and memory transfers can account for the majority of the power budget.
 Jeff Dean on the power and flexibility of deep learning
Jeff Dean on the power and flexibility of deep learning
In this blog post, I’ll present a complementary tutorial on inference in 16 bits (floating point 16 bits aka FP16) on the Jetson TX1, which delivers nearly a 2x performance increase. Notably, 16 bit arithmetic is supported natively on the TX1 (via “SIMD” FP16 FMA, i.e. FP16 x2) and is an excellent feature preview for developing on the Pascal architecture within the Supercomputer-in-a-Box DGX-1.
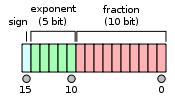
The IEEE 754 half-precision floating-point format with 16 binary bits
First, grab the latest image for your TX1 through Jetpack. NVIDIA provides the software free of charge and it’s packed with goodies such as VisionWorks, System Profiler, and OpenCV4Tegra. If you choose to flash the image, this will displace your current system. When prompted, install all the included packages.
Note, the power of the NVIDIA libraries allow high level API access to FP16 features. Namely, cuDNN library version 3 introduced FP16 storage (activation values) and version 4 introduced arithmetic for convolutions. Let’s proceed by installing the relevant dependencies.
sudo apt-get update
sudo apt-get install aptitude screen git g++ cmake libboost-all-dev libgflags-dev libgoogle-glog-dev protobuf-compiler libprotobuf-dev bc libblas-dev libatlas-dev libhdf5-dev libleveldb-dev liblmdb-dev libsnappy-dev libatlas-base-dev python-numpy libgflags-dev libgoogle-glog-devOnce those are installed, snag the FP16 enabled tree from the NVIDIA Caffe branch.
cd ~
git clone https://github.com/NVIDIA/caffe.git -b experimental/fp16 nvcaffePut this makefile into the nvcaffe directory you’ve created and compile it.
cd nvcaffe
make -j 4That’s it. Now, you can run the forward pass as follows:
./build/tools/caffe_fp16 time --model=models/bvlc_alexnet/deploy.prototxt -gpu 0 -iterations 100This will enable users to explore the high throughput world of FP16. For more realistic inference scenarios, reduce your minibatch size to 1 by editing the deploy.prototxt input shape from 10 to 1, which further increases your forward pass speed.
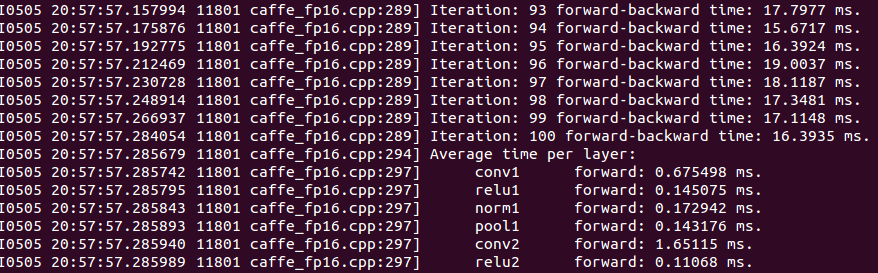 A few zippy roundtrip and layerwise numbers in AlexNet
A few zippy roundtrip and layerwise numbers in AlexNet
Special thanks to Jeff Dean for suggesting the topic of this post and the BVLC group. For more information, read the Jetson TX1 whitepaper. Other interesting tutorials are model fine tuning in our graphical Deep Learning GPU training system DIGITS. Powerful as it is, the TX1 is not meant to handle massive datasets. It’s big brother the DGX-1 is a perfect companion.

The DGX-1: world’s first supercomputer in a box is slightly harder to fit onto your embedded platform