Distributed TensorFlow
Update 4/14/16, the good people at Google have released a guide to distributed synchronous training of Inception v3 network here. It’s the solution to the suggested exercise.
One of the most exciting recent developments is the broad availability of distributed deep learning packages. As Google DeepMind co-founder Demis Hassabis noted, the distributed version of AlphaGo wins about 80% over the single node version. First, let’s survey what distributed training means and how it differs from non-distributed or single node training before we delve into the nuts and bolts of distributed TensorFlow.
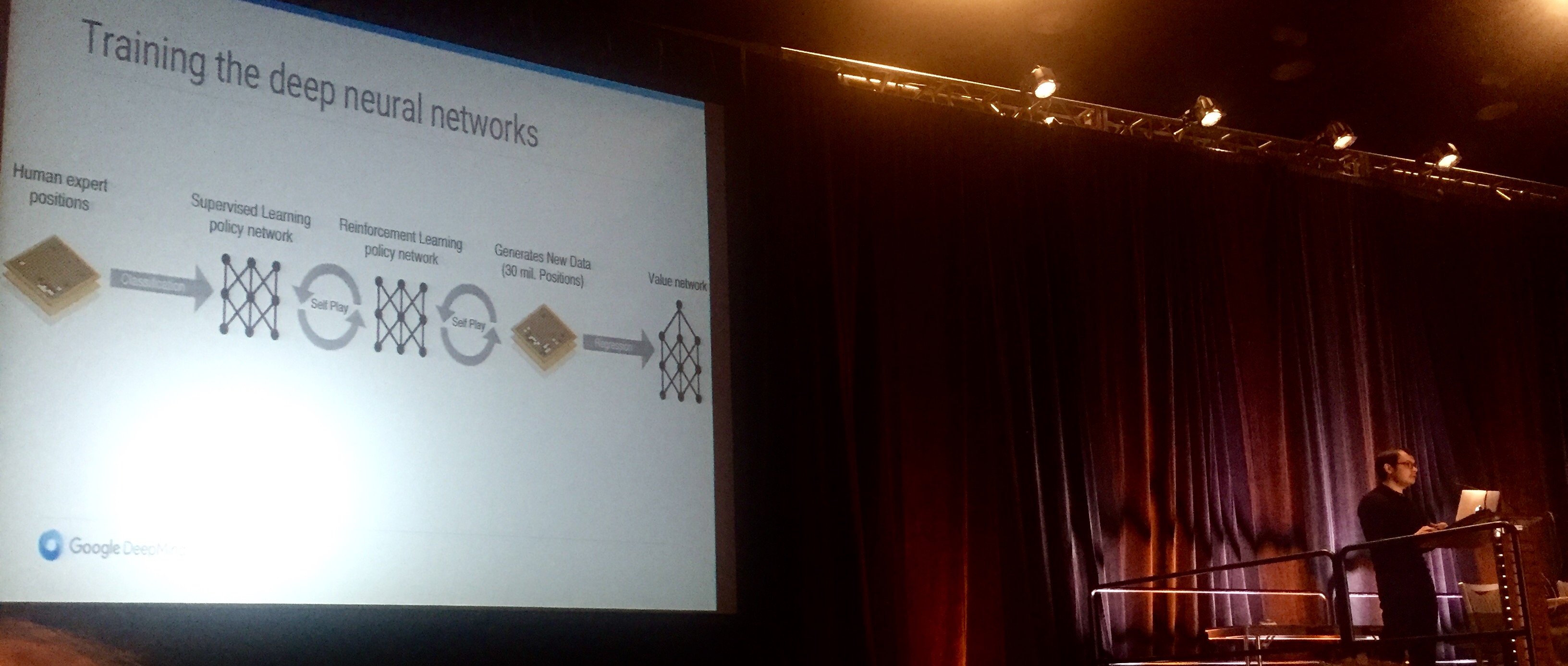
Demis Hassabis delivering his keynote at AAAI 2016. I had the chance to connect with him briefly and he espouses the power of single node and distributed deep learning. The DeepMind Nature paper states they “implemented a distributed version of AlphaGo that exploited multiple machines, 40 search threads, 1202 CPUs and 176 GPUs”
Distributed training uses the resources from a cluster of machines, where a machine is usually a CPU with multiple GPUs attached to a motherboard, while non-distributed training uses the resources from a workstation. A single machine (node) usually has access to anywhere from one to eight GPUs, e.g. the best in-class NVIDIA DevBox is a DL workstation with four Titan X GPUs and appropriate PLX bridges to enable all PCI-E communication lanes to the CPU. There is simplicity in working with one node, but moving to multi-node training scales the ability to perform model and data parallelism (as well the capacity to work larger models). Baidu’s Connectionist Temporal Classification natural language processing (NLP) implementation, Google’s TensorFlow, and AlphaGo’s policy and value networks leverage distributed training.
Again, the community response has been tremendous with releases for major frameworks out in the wild. Major releases include Yahoo’s caffe-on-spark, Twitter’s torch-distlearn, and Google’s TensorFlow distributed runtime.
Now we have laid the groundwork, it’s time to setup distributed TensorFlow. We’ll setup an environment in Ubuntu 14.04 sometimes labeled as the Trusty release. We’ll follow John Ramey’s guide with a few modifications for using updated CUDA, cuDNN, and TensorFlow distributed. The components are as follows:
- Ubuntu utilities
- CUDA 7.5
- cuDNN version 4
- Google’s Bazel build tool 0.1.4
- TensorFlow and TensorFlow distributed runtime
Follow the linked guide up until the CUDA repository download through wget. To pull the latest CUDA repositiory run:
sudo dpkg -i cuda-repo-ubuntu1404_7.5-18_amd64.deb
sudo apt-get update
sudo apt-get install cudaThe next step is downloading cuDNN, which is a library with DL primitives optimized on the assembler (GPU architecture) level. We’ll download the latest version available, and later versions are easily accepted in the configuration step below. Note cuDNN has received enormous attention with four releases over the past year. Continue with installation as per the guide until reaching configuration of the Bazel build:
git clone --recurse-submodules https://github.com/tensorflow/tensorflow
sudo TF_UNOFFICIAL_SETTING=1 ./configureConfigure as follows:
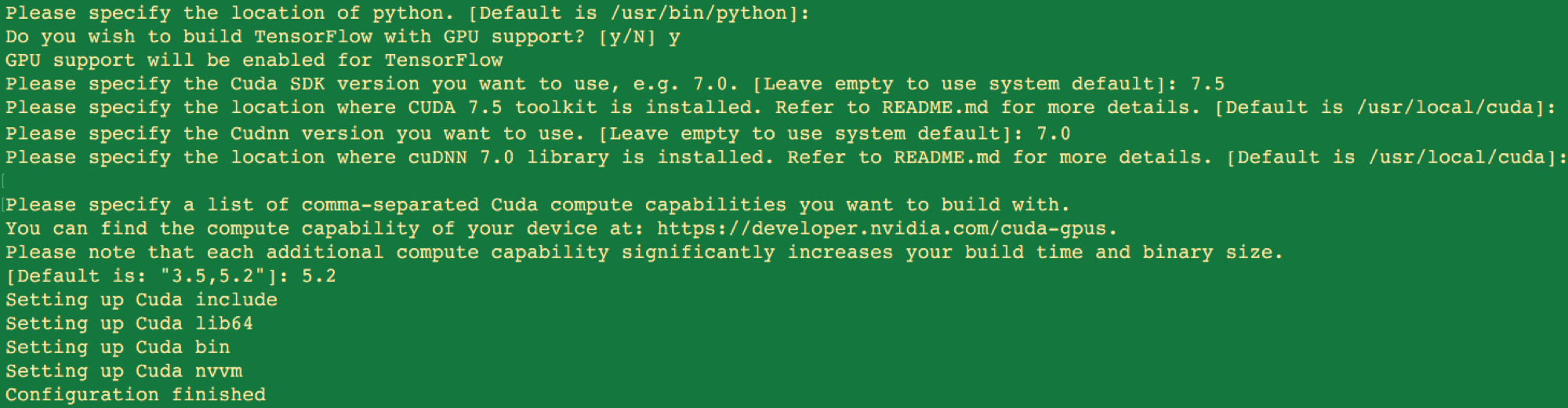
Here we have specified CUDA 7.5 and cuDNN version 4 (sometimes with 7.0 file extension) and accepted the default locations. If your cuDNN version is different, inspect the cuDNN download. In the lib64 folder, the libcudnn.so file will have a postfix with the correct version number to enter. The configuration simply looks for the cuDNN file in the entered directory. For the compute capability, version 5.2 is specified for the Titan X. The previous guide notes 3.0 should be built for K520s, which are the GPU types on AWS. A full list is available here. It’s possible to build for multiple compute capabilities by separating with a comma at the cost of a longer build time. Continue with the installation build from the guide. Remember to change directory into the source directory.
We finish the guide, though making the appropriate substitution to install from the latest version of TF, for example:
bazel build -c opt --config=cuda //tensorflow/tools/pip_package:build_pip_package
bazel-bin/tensorflow/tools/pip_package/build_pip_package /tmp/tensorflow_pkg
sudo pip install --upgrade https://storage.googleapis.com/tensorflow/linux/gpu/tensorflow-0.7.1-cp27-none-linux_x86_64.whlWhew! Now to build the distributed runtime, we add the following build commands.
sudo bazel build -c opt --config=cuda //tensorflow/cc:tutorials_example_trainer
sudo bazel-bin/tensorflow/cc/tutorials_example_trainer --use_gpuThe distributed runtime uses the Google Remote Procedure Call (gRPC) protocol to manage communication. The protocol is an open-source, platform neutral method of communication.
Now the fun part, working with a cluster. Fire up your cluster, which can be simply two GPU instances on your favorite cloud provider. We first launch the gRPC server via commands on each node with an example below:
bazel-bin/tensorflow/core/distributed_runtime/rpc/grpc_tensorflow_server \
--cluster_spec='worker|192.168.555.254:2500;192.168.555.255:2501' --job_name=worker --task_id=0 &The above would be the command for the first node, where ‘worker’ is the name of the cluster and the ip addresses and ports of the nodes follow. A second command should be run at the second node:
bazel-bin/tensorflow/core/distributed_runtime/rpc/grpc_tensorflow_server \
--cluster_spec='worker|192.168.555.254:2500;192.168.555.255:2501' --job_name=worker --task_id=1 &The second node has been assigned a task_id of 1 (0 indexing). How does this work in practice? We’ll perform a simple distributed example using matrix multiplication computed on different nodes.
import tensorflow as tf
import datetime
import numpy as np
n = 4
c1 = tf.Variable([])
c2 = tf.Variable([])
def matpow(M, n):
if n < 1:
return M
else:
return tf.matmul(M, matpow(M, n-1))
t1 = datetime.datetime.now()
with tf.device("/job:worker/task:0/gpu:0"):
A = np.random.rand(1e2, 1e2).astype('float32')
c1 = matpow(A,n)
with tf.device("/job:worker/task:1/gpu:1"):
B = np.random.rand(1e2, 1e2).astype('float32')
c2 = matpow(B,n)
with tf.Session("grpc://192.168.555.254:2500") as sess:
sum = c1 + c2
t2 = datetime.datetime.now()
print "Multi node computation time: " + str(t2-t1)We’ve just used the with tf.device command as usual to explicitly execute aspects of the computation graph on a device. The session calls a node and the gRPC protocol handles communication on the cluster seamlessly (remember to paste the correct IP address for your head node). It’s possible to implement more complicated parameter server training paradigms, and Jeff Dean has mentioned they devote a separate parameter server cluster consisting of over 100 nodes just to handle and update neural network weights!
Within the TensorFlow docs is an excellent section on data parallel multi-GPU training on CIFAR-10. It’s an excellent exercise to modify their multi-GPU code for multi-node, multi-GPU training.
If you want to learn more, there are several distributed DL talks at our GPU Technology conference (link). For any questions regarding distributed TensorFlow, please post on Stack Overflow or the TF Google group where Google’s excellent team and community will provide assistance. Many thanks go to John Ramey and the TF developers.